Computer Organization #
[!NOTE]
在本篇之前,我已经实现了一个非常简单的CPU(感觉都是属于数字电路的内容,当然也是计组的一部分),课程笔记以及资源都来自于B站:Cs Primer。
所以在这里只是简单记录一些感觉有必要的理论知识,还会不断补充。
Cache(存储器层次结构) #
1.DRAM SRAM SSD 机械硬盘读写以及存储,取内存和实际CPU之间的差异性。
2.程序的局部性(Locality):程序倾向于引用邻近于最近引用过的数据项或者是已经引用过的数据项本身(for遍历数组)
a.空间局部性 b.时间局部性
引入:
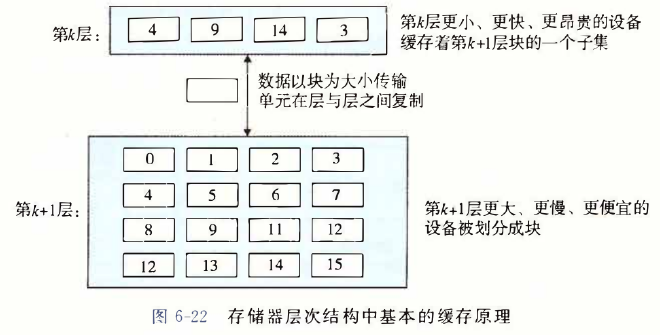
高速缓存存储器 #
1.结构 #
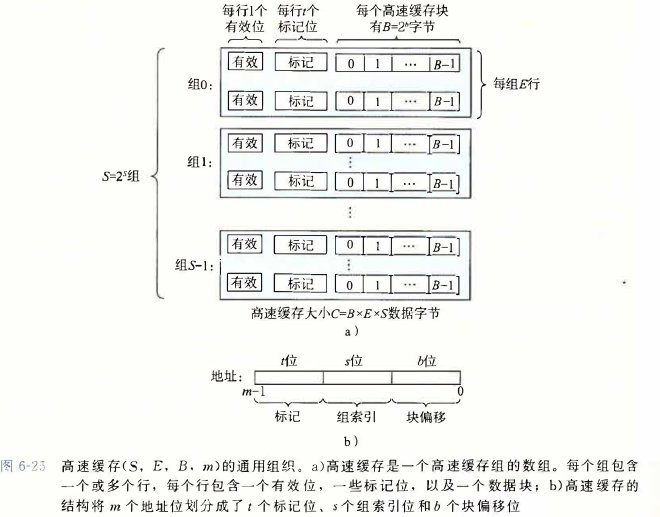
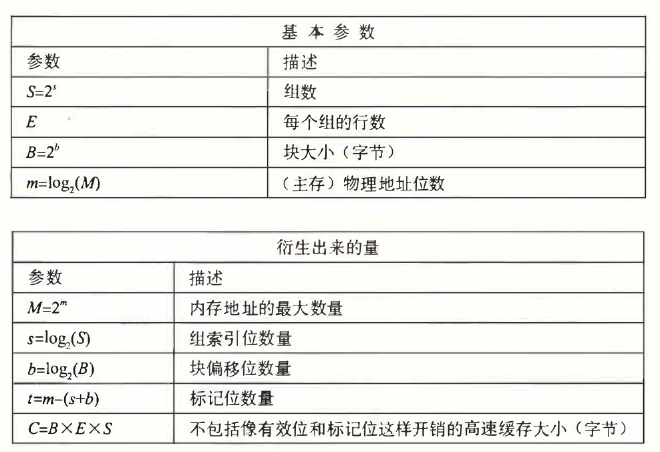
SBE为总的大小。
寻址原理:hash
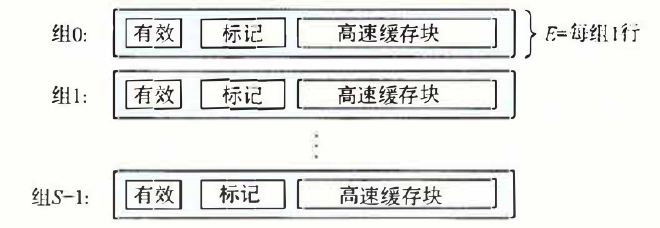
2.直接映射高速缓存(direct-mapped cache) #
就是每组只有一个行
过程
a.组选择
为什么把中间的位作为组索引而不是更高的位?
如果高位做索引,那么很容易把一堆连续的块映射到一组高速缓存块里面,这样不符合空间局部性。
中间的随机性相对更大一些。
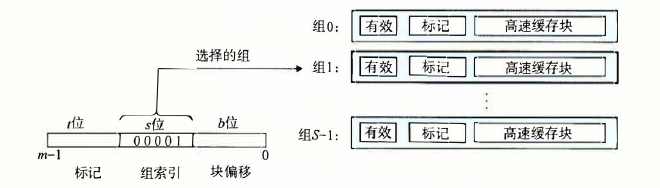
b.找到了组,进行行匹配
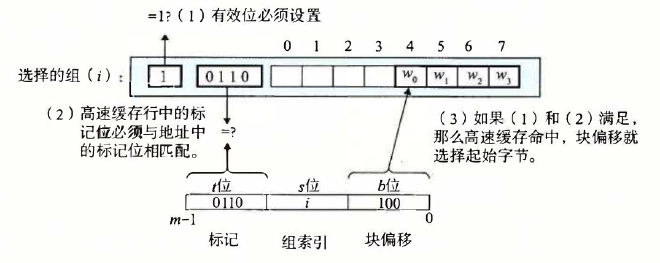
c.根据块偏移位来寻找第一个字节的位置
d.如果没有命中,从下一级内存中取相应的内存块并且直接做替换的操作
e.实际过程:开始缓存为空,冷不命中,从L2中加载数据到L1,然后返回,接着假如标志位不相同,发生冲突不命中,进行替换操作。
d.冲突不命中常见:thrash,高速缓存反复的加载和驱逐相同的一些组。
3.组相联高速缓存(set associative cache) #
就是每个组包含多于一个的行
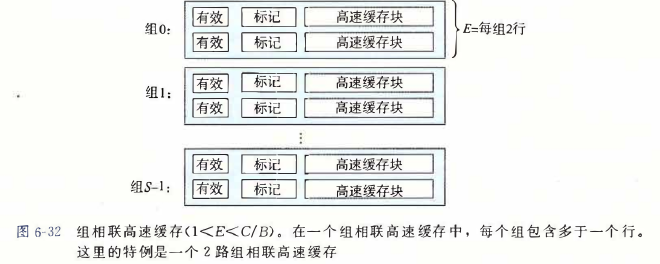
和每个行进行一次匹配
LFU和LRU策略
4.全相联高速缓存(fully asscociative cache) #
就是只有一个组,里面有很多行
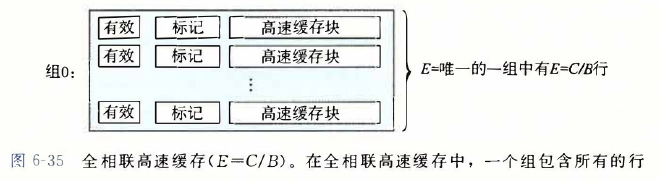
没有组的选择,只有标记位和块偏移。
单周期多周期处理器 #
一个时钟周期内完成一条指令
多周期就是一条指令多个时钟周期
流水线技术 #
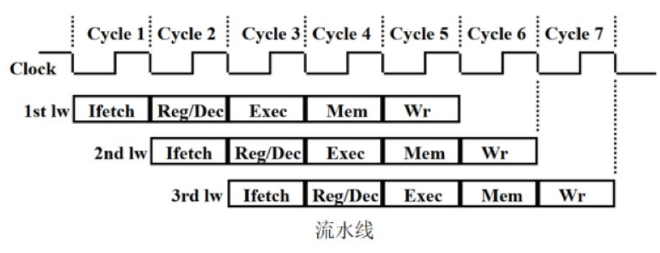
五阶段流水线 #
把每个指令都填充成五个阶段,防止冲突
流水线冒险 #
结构冒险:硬件资源产生冲突 #
数据冒险:逻辑上的数据依赖性产生冲突 #
控制冒险:跳转到别的指令,导致流水线之前准备的指令无效 #
解决:分支预测(动态)
在X86系统上编写和运行程序 #
一个C程序处理流程 #
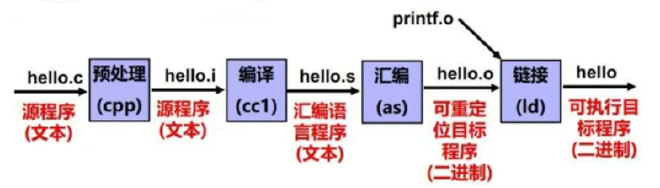
预处理-编译-汇编-链接-程序加载执行
假设我们有文件main.c hello.c
gcc main.c hello.c //这一条指令包含了上述的四个步骤
gcc -E hello.c -o hello.i //这表示对于文件进行预处理 -o是指定名称(擦除并且进行复制粘贴的流程)
gcc -S hello.i -o hello.s //把预处理之后的文件处理成汇编代码
gcc -c hello.s -o hello.o //汇编成一个二进制文件,但是不进行链接的操作
工具:readelf(查看段的偏移) objdump(反汇编) hexdump(查看二进制文件的机器码)
gcc main.o hello.o //直接将两个文件进行链接,如下是链接的过程
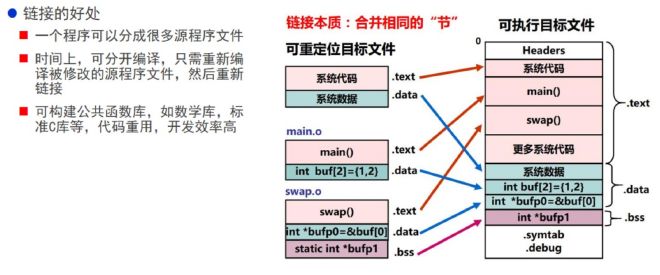
接着是程序加载执行的流程
常见X86汇编指令 #
可以参照CSAPP熟悉基本语法,达到能读的要求即可
[!TIP]
jmp类条件跳转指令之前可以跟其他许多指令
比如 subl a,b 也可以看a和b之间满足的条件
64位使用的寄存器 #
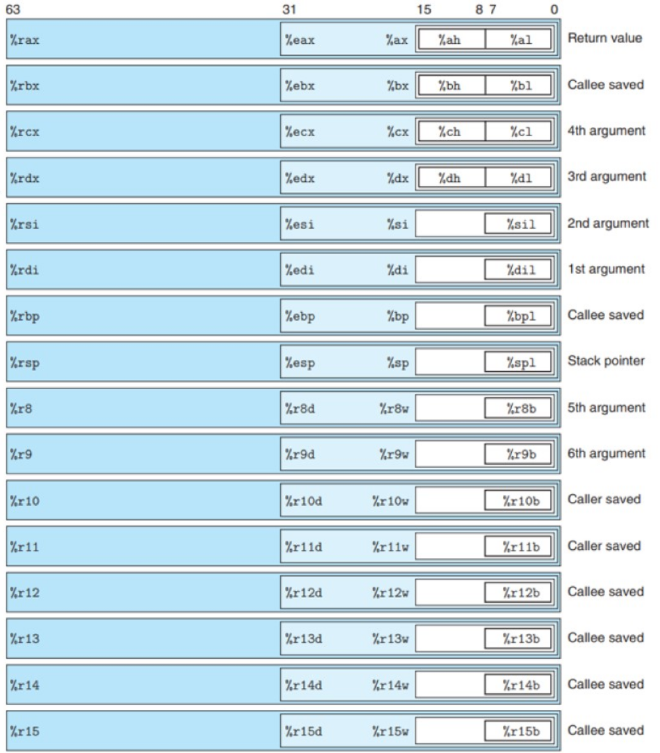
数据传送指令 #
move:不能从内存直接到内存传送 #
[!NOTE]
我看过好几遍书,但是我感觉自己最难理解的地方就是函数的调用以及递归这里的东西,建议大家从push这里开始细细理解。
push指令: #
1.把栈指针减去8,得到栈顶位置,此时栈顶还没有元素。2.把目的操作数放到栈顶。(push只要一个byte,栈上只是放了一堆data,和寄存器,和内存都没有关系)
那么pop指令同理:1.把栈顶的值读入一个目标寄存器。2.把栈指针加8。
条件控制 #
if for while等语句都是条件跳转来实现的
switch语句当case范围较大时也是条件跳转,当范围较小是利用跳转表,一个连续数组的值域包含了所有的case情况(并且case的数量较多)
*Process(过程) #
控制 + 传递 + 内存管理
运行时栈(提前准备) #
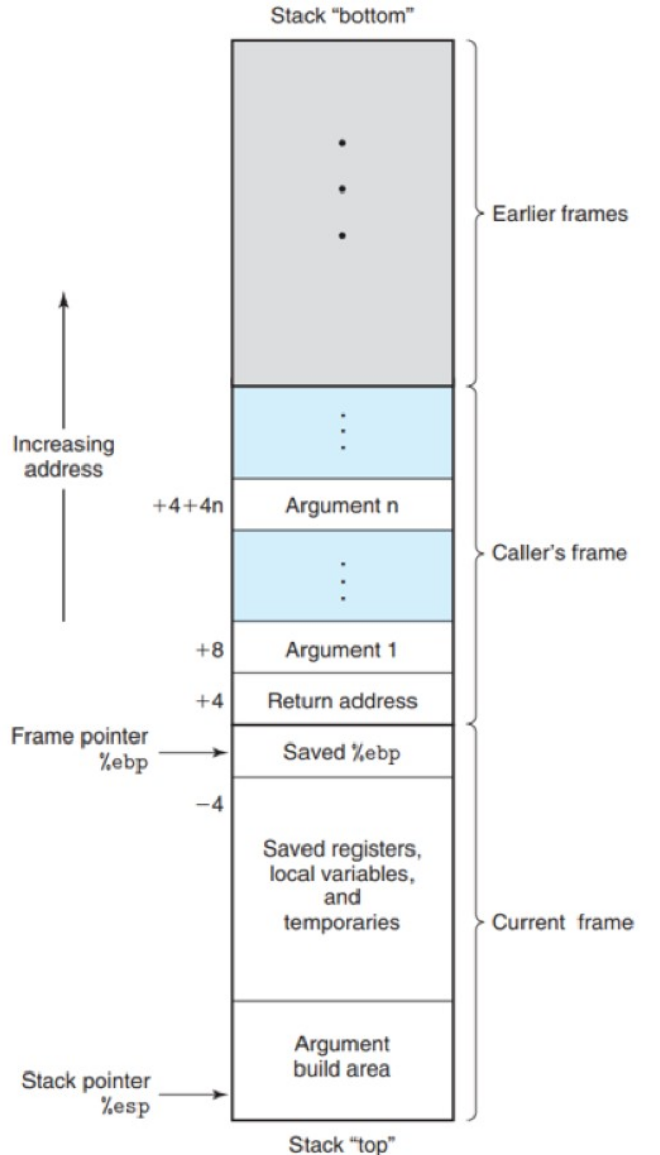
P去调用Q,首先存放返回地址,表明Q返回时从P的哪个位置开始执行,这个地址也是P栈帧的一部分。
接着为Q分配一个栈帧,大多数的栈帧都是定长的,通过寄存器传递参数,如果大于6个,P在调用Q之前提前在自己的栈帧里存储好这些参数。
转移控制(怎么交接控制权利) #
call:把rip的值设置成callee的首地址,这样就把执行权利转换,接着把call指令下一条指令的地址压入栈中。
ret:把压入栈的地址弹出来,并且把rip的值设置成这个地址,这样就交还了控制权利。
数据传送(怎么给Callee传递一些参数) #
在参数小于6个的情况下,我们直接用寄存器来传递,用rax来获得调用方法的返回值即可。
在上图的Current frame中有一个Argument build area,这就是一个参数构造区,如果它也要调用一个参数多于6个的方法,那么就要提前在自己的栈帧里准备好,再执行call指令(注意:第七个参数会在栈的顶部)。
栈上的局部存储(Callee中的局部变量是怎么实现的) #
比如局部变量太多,要取局部变量的一个地址,或者局部变量是数组及结构体等。
还是上图,参数构造区之上就是我们减少栈指针分配给局部变量的空间。
下例出自CSAPP
long swap_add (long *XP , long * yp)
{
long x = *xp ;
long y = * yp ;
*xp = y ;
*yp = x ;
return x + y ;
}
long caller ()
{
//要处理以下两个局部变量,我就要为他们产生地址。
long argl = 534 ;
long arg2 = 1057 ;
long sum = swap_add (&argl , &arg2) ;
long diff = argl - arg2 ;
return sum * diff;
}
以下是汇编代码
long caller()
caller:
subq $16 , %rsp
movq $534 , (%rsp)
movq $1057 , 8(%rsp)
leaq 8(%rsp) , %rsi
movq %rsp , %rdi
call swap_add ;这里的细节:方法虽然已经返回(返回之后之前压入的返回地址就会被弹出),但是栈帧还在,所以分配的局部变量还在
movq (%rsp) , %rdx
subq 8(%rsp) ,%rdx
imulq %rdx , %rax
addq $16 , %rsp ;此时栈帧不存在,会被后来的data覆盖掉
ret
栈帧分配到底拿来干嘛了?
看下图:
分配栈帧,先用来存放本方法要用的局部变量,接着是多于6个的参数从右至左依次压入栈中,然后call,注意,不要混淆局部变量和传递的参数,在被调用的方法中是不会用前一个方法栈帧中的局部变量的。
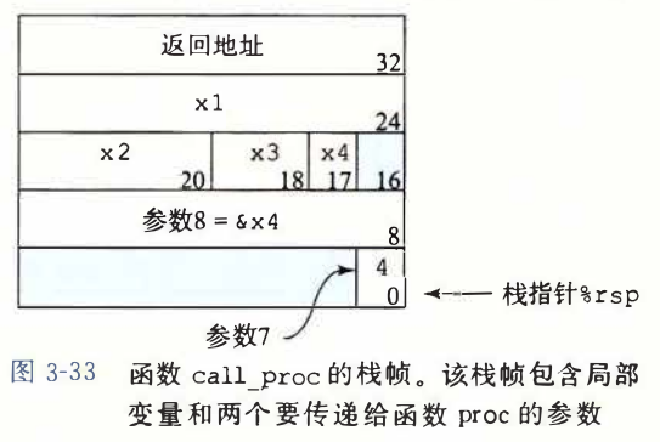
寄存器中的局部存储空间 #
🔹 这些寄存器主要用于什么? #
1. 存储局部变量 #
(这也是一种存储局部变量的方法,比如在for循环中的index)
如果一个函数有局部变量,但寄存器分配不足,编译器可能会把一些变量保存在被调用者保存寄存器里,避免频繁访问栈(比栈上的变量访问快)。
2. 维持长期变量(Long-lived variables) #
如果某个变量在整个函数生命周期内都会被使用,而非临时数据,就可能放在 %rbx、%r12-%r15 这些寄存器里。
3. 维护栈帧指针(%rbp)
#
虽然现代编译器可能会省略栈帧指针(Frame Pointer Omission, FPO),但在调试模式下,%rbp 仍然用于保持当前函数的栈基址,帮助回溯调用栈。
4. 传递跨函数调用的值 #
在一些情况下,如果一个值需要在多个函数调用之间保持不变,就可能存入被调用者保存寄存器,比如:
- 递归函数中,某些参数可能需要跨多次递归调用保持不变。
- 在协程或上下文切换的代码里,某些寄存器可能存储特定的任务状态。
递归过程 #
到这里,理解递归过程就是简单的了,调用自己和调用任何一个过程都是类似的,每个函数都有自己的私有的栈帧。
我们难理解的情况是栈帧里东西太复杂的情况。
数组的分配和访问 #
1.指针访问,如果是地址,就用leaq加载有效地址,如果是取值就用mov指令即可。
2.多维数组
3.定长变长数组以及结构体
关于缓冲区溢出问题 #
C语言基础 #
关于位运算的技巧
宏定义函数多行用\分开,用do {……} while(0)吃掉;(细节问题)
内联函数:类似宏定义,调用的函数不跳转,直接展开,节约资源(根据编译器的情况而定)
static inline int(...){......} //一般这样定义在头文件里使用
关于C语言不再赘述
浮点数详解 #
浮点数存储形式 #
(小数点浮动)进制转换(数字电路内容)
[!NOTE]
IEEE754典中典

这里的尾数其实指的就是小数点之后的二进制表示:
比如2.5 = 10.1b
即 $$ 2.5 = 1.01*2^1 $$
[!NOTE]
这是一个规格化的浮点数,所谓规格化,我们默认一个浮点数是大于1的,即有一个隐含的前导1,我们只在尾数的23位中存储小数点的部分即可,但是如果指数部分为0,但是尾数不为0,这就是一个非规格化的浮点数,计算的规则已经发生了改变,此时的指数为1-bias,为了产生平滑的过渡。
非规格化浮点数及舍入的问题 #
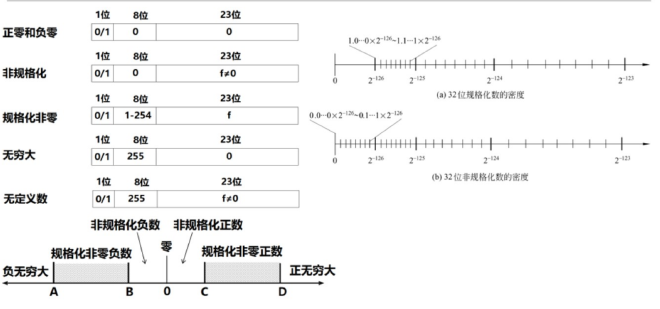
舍入:就近舍入,相同0优先
指数部分越大,密度变小,精度就会变低
浮点数的运算 #
先把指数设置相同,再相加这会导致大数吃掉小数的情况产生
采用如下的累加算法

比较问题:0.1 + 0.2 != 0.3(无限不循环小数相加导致的)
[!NOTE]
还有一个值得注意的点是转换类型时候的最近偶数舍入(银行家舍入),这有利于减少累积舍入的误差。
课后作业 #
此时我们去做CSAPP的3个lab,并且把CSAPP2,3章的课后习题都解决一遍(我懒的写第二章了,我只写一下第三章的内容)
1.datalab
2.bomblab(gdb的使用,很有难度,我觉得可以先多看看书,做一下练习和课后习题,理解之后再去上手)
gdb常用指令(来自https://arthals.ink/blog/bomb-lab作为参考的blog)
p $rax # 打印寄存器 rax 的值
p $rsp # 打印栈指针的值
p/x $rsp # 打印栈指针的值,以十六进制显示
p/d $rsp # 打印栈指针的值,以十进制显示
x/2x $rsp # 以十六进制格式查看栈指针 %rsp 指向的内存位置 M[%rsp] 开始的两个单位。
x/2d $rsp # 以十进制格式查看栈指针 %rsp 指向的内存位置 M[%rsp] 开始的两个单位。
x/2c $rsp # 以字符格式查看栈指针 %rsp 指向的内存位置 M[%rsp] 开始的两个单位。
x/s $rsp # 把栈指针指向的内存位置 M[%rsp] 当作 C 风格字符串来查看。
x/b $rsp # 检查栈指针指向的内存位置 M[%rsp] 开始的 1 字节。
x/h $rsp # 检查栈指针指向的内存位置 M[%rsp] 开始的 2 字节(半字)。
x/w $rsp # 检查栈指针指向的内存位置 M[%rsp] 开始的 4 字节(字)。
x/g $rsp # 检查栈指针指向的内存位置 M[%rsp] 开始的 8 字节(双字)。
info registers # 打印所有寄存器的值
info breakpoints # 打印所有断点的信息
delete breakpoints 1 # 删除第一个断点,可以简写为 d 1
3.attacklab(模拟攻击)
[!NOTE]
上述工作会花费很长时间,但是欲速则不达,如果难以下手,你可以参考CSDIY上的一些推荐博客。
链接简单解读 #
Static Linking #
可以理解是怎么把你写的多文件程序整合在一起运行。

可重定位目标文件的分析(Relocatable File) #
单个文件汇编之后,后缀为.o的文件就是一个可重定位目标文件。
(用以下的两个程序)
readelf -a main.o //分析elf文件内容
hexdump -C main.o //直接查看文件的二进制信息

符号表信息 #

弱符号和强符号 #

可执行文件 #
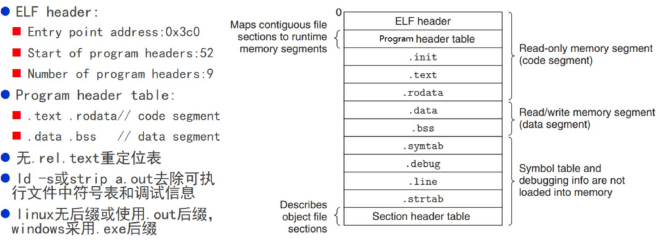
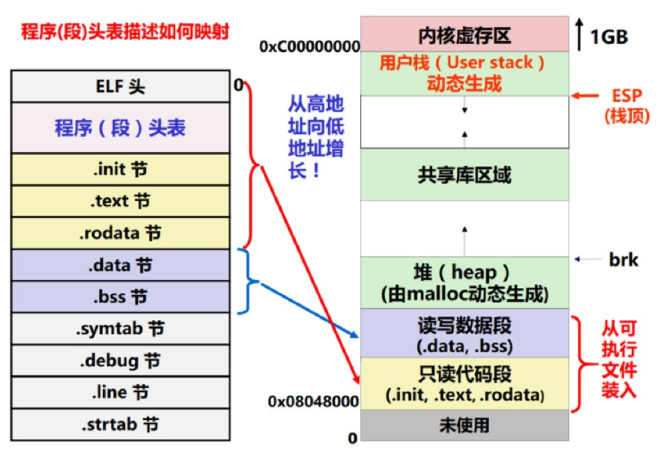
查看可执行文件的Program Header(可执行文件是怎么被加载执行的?)
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
LOAD 0x001020 0x00800020 0x00800020 0x00198 0x00198 R E 0x1000
LOAD 0x002000 0x00801000 0x00801000 0x00038 0x00050 RW 0x1000
GNU_STACK 0x000000 0x00000000 0x00000000 0x00000 0x00000 RW 0x10
Section to Segment mapping:
Segment Sections...
00 .text .rodata
01 .data .bss
02
静态链接的过程 #

/* Simple linker script for os user-level programs.
See the GNU ld 'info' manual ("info ld") to learn the syntax. */
//一个简单的linker脚本
OUTPUT_FORMAT("elf32-i386", "elf32-i386", "elf32-i386") //输出格式
OUTPUT_ARCH(i386) //架构类型
ENTRY(main) //程序的入口点(main函数)
SECTIONS {
/* Load programs at this address: "." means the current address */
//在这个地址对程序进行加载
. = 0x800020;
//以下都是把每个目标文件中的相同的段合并到新的段
.text : {
*(.text .stub .text.* .gnu.linkonce.t.*)
}
PROVIDE(etext = .); /* Define the 'etext' symbol to this value */
.rodata : {
*(.rodata .rodata.* .gnu.linkonce.r.*)
}
/* Adjust the address for the data segment to the next page */
//转页进行存储,以上的页就可以设置成ro的一个页
. = ALIGN(0x1000);
.data : {
*(.data)
}
//记录下来,把.bss段设置成0
PROVIDE(edata = .);
.bss : {
*(.bss)
}
PROVIDE(end = .);
/DISCARD/ : {
*(.eh_frame .note.GNU-stack .comment)
}
}
重定位信息 #
