MySQL语句简单教程 #
MySQL #
本文仅仅是笔者对于SQL语句的简单熟悉和复习的笔记,所以并不会对于更深刻的细节进行考究,也不会介绍怎么安装和配置MySQL的环境以及为什么我们要使用关系型数据库。
1.Table #
创建表:有B格的创建一张表

查看表结构:desc
delete:drop table if exists;
修改表字段
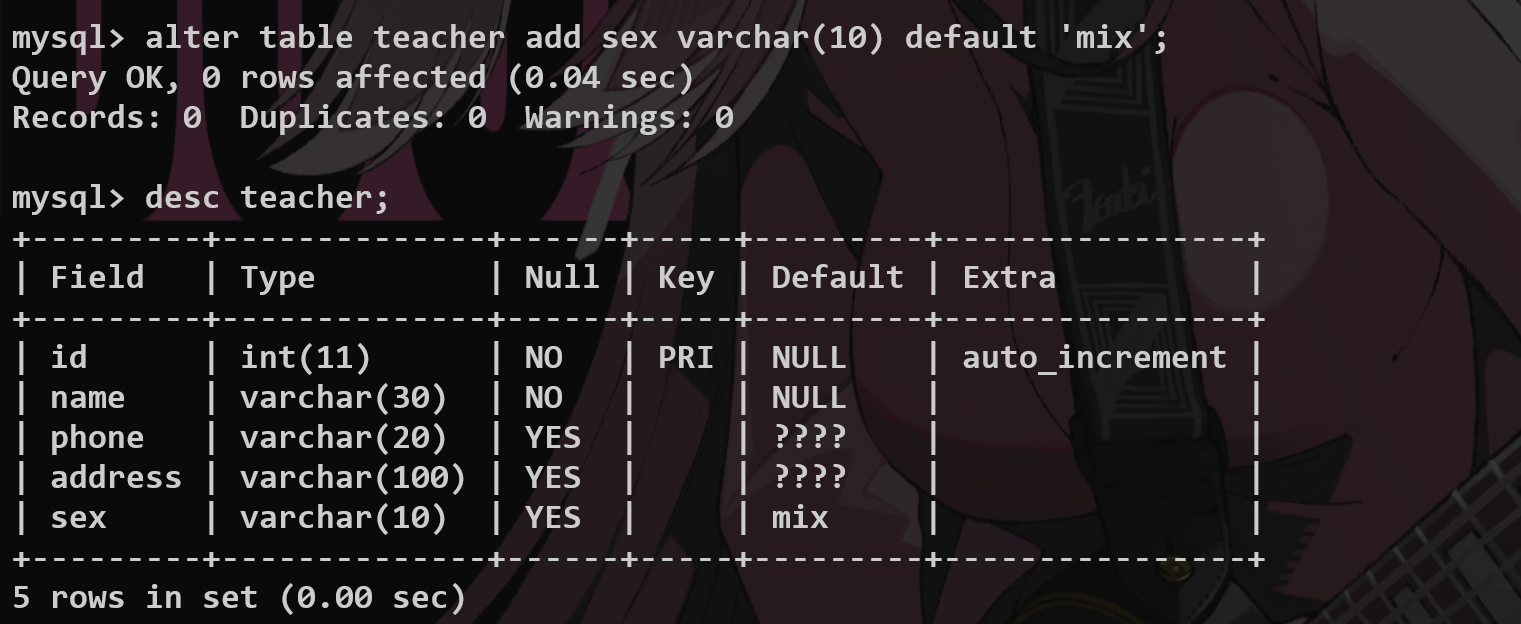
**`alter table <name> add/change/modify <name> <name1>……`**
**`alter table <name1> rename to <name2>`**
delete from student;
绝对不要用这样的方式去清空一张表1.遍历删除,会浪费时间和资源2.若设置auto increment 主键,那么再加入数据的时候会从原来增长的部分继续
truncate table student;
直接报废表并且创建一张和原来一样的新表
2.Data #
update data:
`update <tablename> set <field>=<newValue> where <field>=<value>;`
search data from table:
`select <fieldname,…> from <tablename>;`
`select* from<tablename>`
database definition language: create drop alter show
data manipulation language: insert delete update select
database control language: 关于数据库的角色控制?
3.DataType #
Decimal数据存储原理?
enum枚举类型:仅能选取其中已经有的元素来存储,代表从一开始的数字
set集合类型:能从集合中选取多个元素进行存储——用户兴趣标签
set存储原理???
4.列属性完整性(重点) #
auto_increment 必须是 primarykey主键
primary key主键:唯一性—>一组或者一个字段 #
1.保证数据的完整性
2.加快数据的查询速度—用来做表的关联
`alter table <tablename> add primary key (<filedname>......);`添加主键,多个字段就是**组合键**
`alter table <tablename> drop primary key;`
复合主键解决的问题
unique唯一键
和primary的区别:可以为null,不和其他表产生关联,但是必须唯一(null不唯一)
delete:`alter table <tablename> drop index <filedname>;`
comment 注释问题
SQL内注释和代码注释
数据库的完整性问题
Foreign Key(外键约束技术) #
怎么在两张表之间建立联系?
主表:

建立从表:

从表:

`alter table <tablename> add foreign key (<filedname>) references <tablename>(<filedname>);`
`show create table <tablename>;`
查看创建的表结构并且删除外键
当主表中的数据发生变化的时候,从表中的数据应该如何修改?
置空和级联的操作(在创建表的时候就要声明清楚) #
置空:主表中的数据被删除,那么从表中的数据依然保存,但是外键的被删除的字段为NULL;
级联:主表中的数据发生修改,从表中的外键对应字段的数据全部发生修改;

如图:删除——set null

5.数据库设计思维 #
a.基本概念 #
关系:两张表通过共同的字段来确立数据的完整性
行——一条数据——实体
列——一个字段——属性
数据冗余:牺牲空间,提升查询性能(高考总分)
b.实体之间的关系 #
一对多(学生表和食堂消费记录之间的关系)
一对一
多对一
多对多
c.范式 #
Codd第一范式:确保字段的原子性,一个字段不可以再分 2018-2019 —— 2018 2019
Codd第二范式:非键字段必须依赖于主键字段(无关的字段不应当加入,一张表只描述一种信息)
Codd第三范式:消除传递依赖——根据实际情况,我们到底要不要考虑加入数据冗余的处理
6.单表查询 #
a.基本关键字 #
select #

from #
指定要查的表;返回两张表的笛卡尔积

dual #
默认的一个虚拟表,单行单列

where #
限制select查询条件 < ≤ > ≥ or and……
in #
限定查询的字段的值在一个范围之内

between…and… #
限制查询的范围在给定的闭区间内部

is null #
查看是空或者非空,简单
几种常见的聚合函数 #

Q:select count(*) and select count(1); what’s the difference?
like模糊查询——通配符 #

group by分组查询 #
select <function-name>(<fieldname1>) as 'alias1', <fieldname2> as 'alias2' group by <fieldname2>;#要根据哪个字段去查询

比如想求男性和女性的平均年龄:

利用group_concat函数查询对应字段对应的实体

having #
和where一样作为条件筛选,但是:
1.where是根据条件对于实际存在于数据库中的数据进行筛选
2.having对于查询之后的虚拟表使用——比如配合group_by(此时就不能使用where条件来处理)

limit #
选取顺序中的下标范围
select <fieldname> from <tablename> limit <start-index>,<length>;

distinct #
去重复关键字
默认情况下有all
select (all) <fieldname> from <tablename>;

至此,单表查询基础结束。
7.多表查询 #
1.union #
select… + union + DISTINCT + select…
对应字段个数必须相等
2.join #
用两个表创建公共字段进行连接——内连接——有多张表就用多个inner进行连接

select f1,f2 from t1 inner join t2 on t1.f3=t2.f4 (having score > 90);
left join 以左表为一个基准(就算左边没有也要写上去 right join 同理)

cross join返回两张表的笛卡尔积
select* from t1 cross join t2;
natural join自动寻找公共字段并且建立inner join的连接
没有公共字段就返回cross join的结果
using
当两张表的字段完全相同的时候,using指定建立连接的公共字段

8.子查询 #
用一个select语句返回的数据范围作为限制的基准(用in和not in 来控制)

只要存在就全部查询 exists and not exists

至此,所有基础内容结束,以上的内容都是对于一名实习生来说最为重要的内容(每一种语法单独看来都是很好理解的,但是都联合起来的话就显得很困难),以下为扩展:
扩展内容: #
1.视图(View) #
作用:简化SQL查询;掩盖敏感数据
创建视图

以后就可以直接查询

alter修改视图
drop直接删除视图
视图底层算法(在使用子查询创建视图的时候)
unchecked
1.temp table 临时表算法
2.merge 合并算法
2.事务(Transaction) #
处理非常严谨的操作,例如转账等

设置回滚点 并且返回—— rollback to

原子:一个事务不可再分,要么全部执行,要么不执行
隔离:多个事务同时对一个数据库进行操作,不会产生冲突
注意:仅当engine=innodb的时候,才能使用事务
3.index(索引) #
快速查询数据——实习生要理解到什么程度?
4.存储过程 #
提前写好SQL一次执行,有点像函数
利用delimiter设置结束符号

企业规范约束 #
1.库表字段的约束规范 #
是否: is_vip unsigned tiny int length1️⃣ (不能浪费存储)
dont’s
不能有大写字母,
不能以数字开头,
下划线之间不能只有数字,
不能出现负数,
不能有关键字
凡是有小数,必须用decimal数据类型
dos
主键:pk_key,
字符串长度较小时,请使用char,
强制存在的字段:
1.id(unsigned bigint 单表的时候必须自增 primary key)
2.create_time(datetime)
3.update_time(datatime),
2.索引规范 #
有某些必须:唯一索引
不能查两个以上的关联查询
varchar上建立索引:建立索引的长度
3.SQL开发约束 #
count(xx,xxx,xx) count(*);
判断为空的方法:
where name = null ;
where name is null;
不要使用外键和级联(尤其是在高并发的项目中,牵一发而动全身)
这些问题在Server层解决
不允许使用存储过程(很难调试,其中的SQL写错了怎么办,和脚本不一样,移植性也很差)
utf-8作为标准编码格式
4.其他约束 #
ORM框架查询不能写*
Q:pujo类bool类型不能加is?